
برچسب های مهم

 دستور کار آزمایشگاه فرآورده های نفتی
دستور کار آزمایشگاه فرآورده های نفتی دانلود جزوه بهره برداری – مهندسی نفت
دانلود جزوه بهره برداری – مهندسی نفت جزوه حفاری مهندسی نفت
جزوه حفاری مهندسی نفت ۵۰۴ واژه مطلقا ضروری زبان انگلیسی — مجموعه یادگیری ماکزیمم
۵۰۴ واژه مطلقا ضروری زبان انگلیسی — مجموعه یادگیری ماکزیمم کامل ترین جزوه گرامر زبان انگلیسی
کامل ترین جزوه گرامر زبان انگلیسی دانلود مجموعه ۵۵ کتاب با موضوعات روانشناسی، مدیریت و موفقیت
دانلود مجموعه ۵۵ کتاب با موضوعات روانشناسی، مدیریت و موفقیت دانلود فایل آموزشی آشنایی با شیرهای فوران گیر
دانلود فایل آموزشی آشنایی با شیرهای فوران گیر کامل ترین جزوه تایپی ریاضیات مهندسی از استاد احسائیان
کامل ترین جزوه تایپی ریاضیات مهندسی از استاد احسائیان دانلود جزوه دوره ی آموزشی پایپینگ (Piping Training Course)
دانلود جزوه دوره ی آموزشی پایپینگ (Piping Training Course)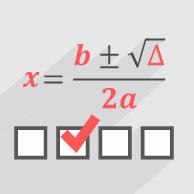 جزوه ی آموزش کامل تکنیک های تست زنی مهندسی معکوس
جزوه ی آموزش کامل تکنیک های تست زنی مهندسی معکوس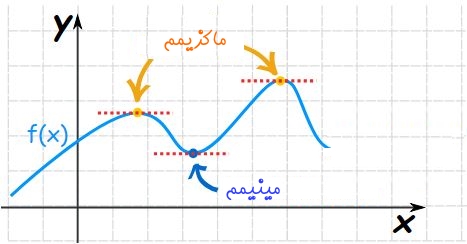 ماکزیمم و مینیمم تابع به زبان ساده
ماکزیمم و مینیمم تابع به زبان ساده انتگرال — به زبان ساده
انتگرال — به زبان ساده انتگرال سطحی از صفر تا صد
انتگرال سطحی از صفر تا صد روسیه در بحبوحهی بحران جاری نفت، کاری کارستان کرده و گوی سبقت را در تشکیل یک کارتل جدید نفتی از دیگران ربوده است
روسیه در بحبوحهی بحران جاری نفت، کاری کارستان کرده و گوی سبقت را در تشکیل یک کارتل جدید نفتی از دیگران ربوده است نمودار های بندش سیمان«CBL/VDL»
نمودار های بندش سیمان«CBL/VDL» رشته مهندسی نفت در کانادا
رشته مهندسی نفت در کانادا این قسمت می خواهیم با چند ابزار بهره برداری آشنایی پیدا کنیم. در بخش زیر به توضیح این مطلب پرداخته ایم .
این قسمت می خواهیم با چند ابزار بهره برداری آشنایی پیدا کنیم. در بخش زیر به توضیح این مطلب پرداخته ایم . گفتگو با مهندس مهدی گندم گون عضو بنیاد ملی نخبگان درمورد کلیات رشته مهندسی نفت
گفتگو با مهندس مهدی گندم گون عضو بنیاد ملی نخبگان درمورد کلیات رشته مهندسی نفت کتاب تجوید مصور رایگان
کتاب تجوید مصور رایگان کتاب مسائل حل شده در زمین آمار
کتاب مسائل حل شده در زمین آمار کتاب مقدمه ای برژئومکانیک نفت
کتاب مقدمه ای برژئومکانیک نفت کتاب مرجع کامل مهندسی مخازن نفت وگاز(جلد اول)
کتاب مرجع کامل مهندسی مخازن نفت وگاز(جلد اول) مدلسازی استاتیک مخازن نفت باPETREL
مدلسازی استاتیک مخازن نفت باPETREL کتاب زمین شناسی ساختمانی وتکتونیک
کتاب زمین شناسی ساختمانی وتکتونیک کتاب تجزیه وتحلیل سیگنالها و سیستم ها (بخش دوم)
کتاب تجزیه وتحلیل سیگنالها و سیستم ها (بخش دوم) کتاب چاه نگاری(ویرایش سوم)تجزیه وتحلیل سیگنال ها وسیستم ها(بخش اول) دانلود جزوه بهره برداری – مهندسی نفت جزوه حفاری مهندسی نفت کامل ترین جزوه تایپی ریاضیات مهندسی از استاد احسائیان کامل ترین جزوه گرامر زبان انگلیسی دانلود فایل آموزشی آشنایی با شیرهای فوران گیر
کتاب چاه نگاری(ویرایش سوم)تجزیه وتحلیل سیگنال ها وسیستم ها(بخش اول) دانلود جزوه بهره برداری – مهندسی نفت جزوه حفاری مهندسی نفت کامل ترین جزوه تایپی ریاضیات مهندسی از استاد احسائیان کامل ترین جزوه گرامر زبان انگلیسی دانلود فایل آموزشی آشنایی با شیرهای فوران گیر دانلود دستور کار آزمایشگاه مکانیک سیالات – مهندسی شیمی و نفت دانلود جزوه دوره ی آموزشی پایپینگ (Piping Training Course)
دانلود دستور کار آزمایشگاه مکانیک سیالات – مهندسی شیمی و نفت دانلود جزوه دوره ی آموزشی پایپینگ (Piping Training Course) جزوه تایپ شده فارسی درس مکانیک سنگ
جزوه تایپ شده فارسی درس مکانیک سنگ دانلود جزوه زمین شناسی ساختمانی – مهندسی نفت
دانلود جزوه زمین شناسی ساختمانی – مهندسی نفت کتاب مهندسی سیال حفاری (Drilling Fluid Engineering) جزوه ی آموزش کامل تکنیک های تست زنی مهندسی معکوس دانلود مجموعه ۵۵ کتاب با موضوعات روانشناسی، مدیریت و موفقیت
کتاب مهندسی سیال حفاری (Drilling Fluid Engineering) جزوه ی آموزش کامل تکنیک های تست زنی مهندسی معکوس دانلود مجموعه ۵۵ کتاب با موضوعات روانشناسی، مدیریت و موفقیت






